Streamlining Node.js: Mastering the Art of Streams
Streamlining Memory Usage: Unleashing the Power of Node.js Streams


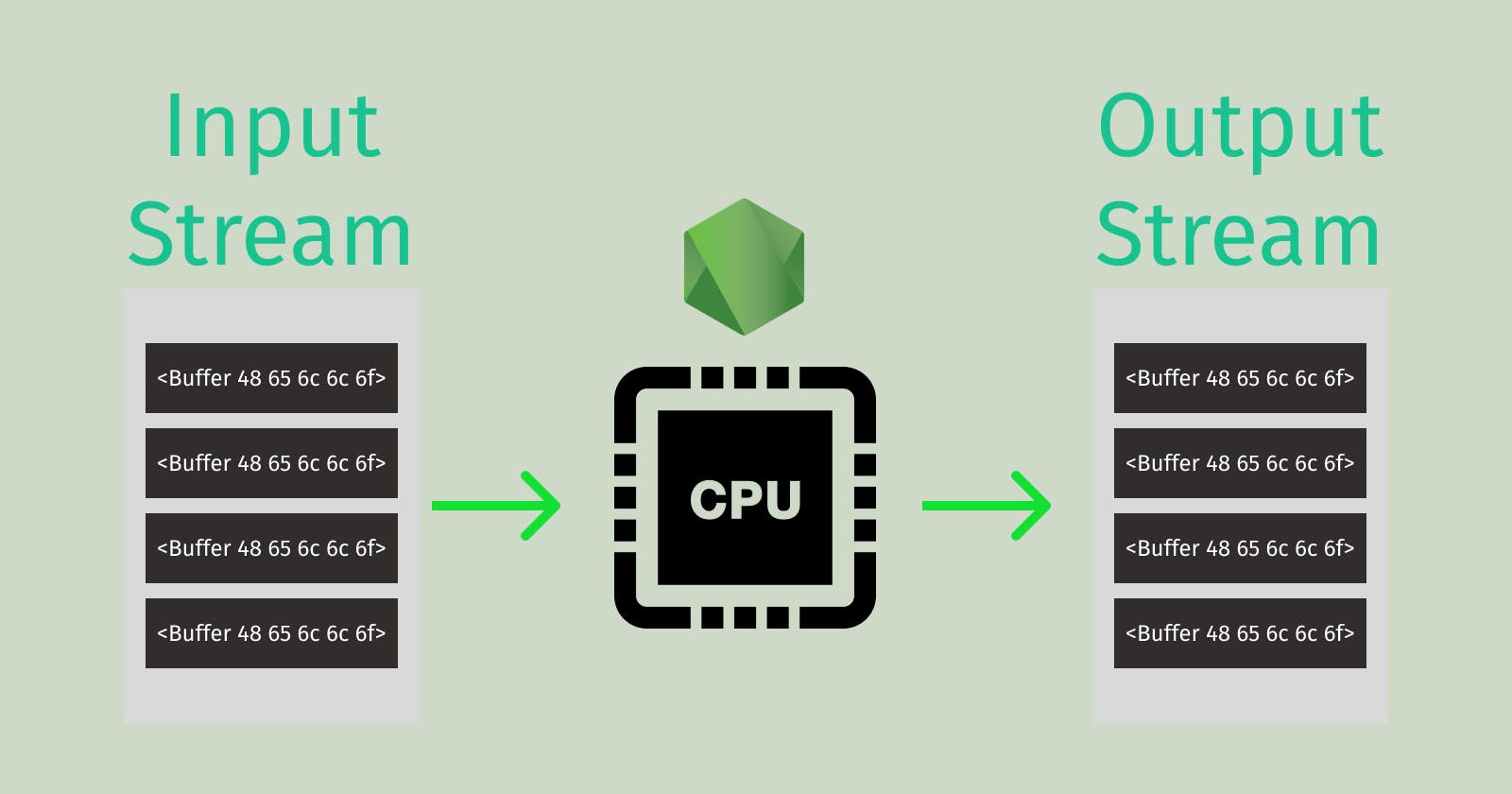
Streams, at their core, are simply a flow of sequences of binary digits (0s and 1s) that encode instructions or data, facilitating communication within and between devices. Whether you're downloading a PDF from the internet or pressing a key on your keyboard, these actions generate binary streams. Despite being one of the most powerful features in the Node.js runtime environment, streams remain one of the most misunderstood concepts. Node.js harnesses the capability of streams through Buffers, as JavaScript itself isn't ideally suited for handling raw binary data. In this article, we will delve into the world of Node.js streams, unraveling what they are and how to utilize them to create memory-efficient code.
Understanding buffers is a fundamental prerequisite for grasping the concept of streams. LinK: https://ritwikmath.hashnode.dev/decoding-nodejs-buffers-an-in-depth-exploration-of-binary-data-handling
What is Node Stream?
Think of Node.js streams as more than just reading and writing files – they're all about managing data flow. In fact, reading and writing operations don't entirely encapsulate the essence of streams. Every stream object is essentially an instance of Node's EventEmitter class. When a stream is ready for reading, writing, or even both, it's like an event emitter sending a signal to the client code, saying, 'Hey, I'm ready!' The data in the stream is like a sequence of binary information stored in your computer's memory. It doesn't really care about what you intend to do with it; it's just there, waiting to be used. When it's no longer needed, the garbage collector will take care of cleaning it up once the event emitter is done with its operation. Node.js request, response objects, process.stdin, process.stdout, createReadStream, createWriteStream, and many more are examples of streams.
Why use Stream?
Imagine you're working with a massive 1GB file in a Node.js application, and your goal is to create a zip archive from it. If you don't use streams, the application loads the entire 1GB file into memory and then creates the zip archive in memory as well. After that, it transfers the zip archive from RAM to disk storage and finally frees up the initial file from memory. The catch is, during this entire process, both the original file and the new zip archive occupy memory, resulting in substantial memory consumption, especially for large files.
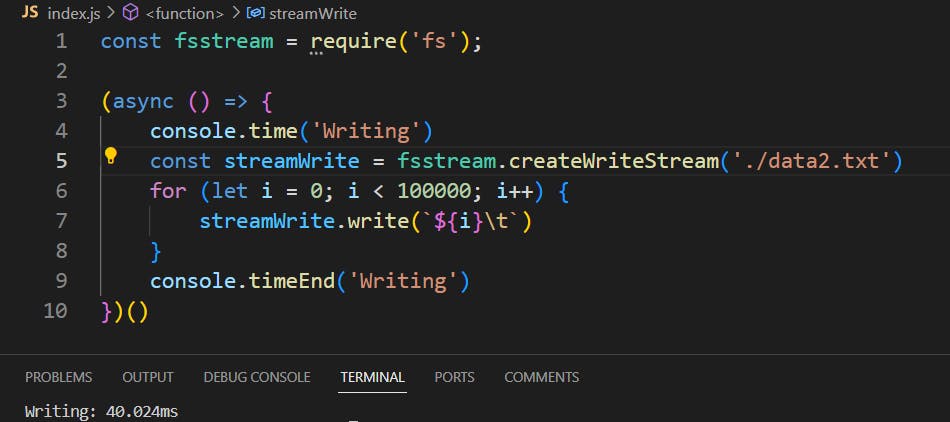
However, when you leverage streams, the application loads only small chunks, usually 64KB by default, into memory. It converts each of these chunks into zip format, and once a chunk is processed, it is promptly released. This means that at any given moment, only a small portion of the file resides in memory, leading to a significantly reduced memory overhead. The system operates with very small units of data at a time, resulting in significantly reduced time for performing operations using streams.
// Write a file using promises
// Time: 1.730 s
const fs = require('fs/promises');
(async () => {
console.time('Writing')
const fileHandle = await fs.open('./data2.txt', 'w')
for (let i = 0; i < 100000; i++) {
await fileHandle.write(`${i}\t`)
}
console.timeEnd('Writing')
})();

// Write a file using stream
// Time: 40.024 ms
const fsstream = require('fs');
(async () => {
console.time('Writing')
const streamWrite = fsstream.createWriteStream('./data2.txt', { highWaterMark: 1 * 1024})
for (let i = 0; i < 100000; i++) {
streamWrite.write(`${i}\t`)
}
console.timeEnd('Writing')
})()
Types of Streams in Node.js
Node streams come in four types: Readable, Writable, Duplex, and Transform. Each type serves a unique purpose in handling data within Node.js.
Readable
A readable stream in Node.js reads binary data in chunks, not as a single buffer, and it provides these chunks for further processing. You can then handle these data chunks as they arrive, rather than storing them all in a single buffer to be used later. This approach allows for more memory-efficient and real-time processing of large data sets.
const fs = require('fs')
const redable = fs.createReadStream('./data.txt')
readable.on('data', data => console.log(data))
Let's talk about a few key events that happen with readable streams, particularly 'close,' 'end,' and 'data.' The 'data' event is pretty interesting. It fires up when the readable stream sends data to the writable stream. If you look at a screenshot, you'll notice that the 'data' event output shows up before 'process.stdout.' Now, the 'close' event happens when there's no more work left to do, like saying goodbye at the end of the day. And the 'end' event is like the stream's way of saying, 'I'm done, no more data to read.' If you look at the console log, the sequence of these events helps you understand how everything flows and makes sense.

Writable
A writable stream is the counterpart to a readable stream in Node.js. While a readable stream is used to read data in small, manageable chunks, a writable stream is used to write data in a similar way, chunk by chunk. Writable stream is commonly used for tasks like writing data to a file, sending data over a network connection, or any other operation where you want to write data sequentially without loading the entire dataset into memory all at once. This is especially important when dealing with large files or streaming data in real time because it helps to conserve memory and maintain the efficiency of your application.
const fs = require('fs')
const writeable = fs.createWriteStream('./data_new.txt')
writeable.write('Hello Developers!')
Let's shift our focus from readable streams to writable streams and explore some important events that occur in this context, specifically 'drain,' 'finish,' and 'error.' Writable streams are like the other half of the conversation, allowing us to send data out.
Among these events, the 'drain' event is quite interesting. It's like a traffic light turning green after a brief stop, indicating that you can proceed with writing more data. This is especially important when you need to balance the flow of data and avoid overwhelming the system's memory.
function writeOneMillionTimes(writer, data, encoding, callback) {
let i = 1000000;
write();
function write() {
let ok = true;
do {
i--;
if (i === 0) {
// Last time!
writer.write(data, encoding, callback);
} else {
// See if we should continue, or wait.
// Don't pass the callback, because we're not done yet.
ok = writer.write(data, encoding);
}
} while (i > 0 && ok);
if (i > 0) {
// Had to stop early!
// Write some more once it drains.
writer.once('drain', write);
}
}
}
Next, we have the 'finish' event, which occurs when all the data has been successfully written. It's like a job well done, signaling that the writing process is complete.
const writer = getWritableStreamSomehow();
for (let i = 0; i < 100; i++) {
writer.write(`hello, #${i}!\n`);
}
writer.on('finish', () => {
console.log('All writes are now complete.');
});
writer.end('This is the end\n');
However, sometimes things don't go as planned, and that's where the 'error' event comes in. It tells us when something went wrong during the writing process, like when you encounter a roadblock on your journey.
const { Writable } = require('node:stream');
const myStream = new Writable();
const fooErr = new Error('foo error');
myStream.destroy(fooErr);
myStream.on('error', (fooErr) => console.error(fooErr.message));
Understanding these writable events is crucial for efficient data handling in Node.js streams. Just like with readable streams, knowing the sequence and meaning of these events helps make sense of the data writing process.
Duplex
Duplex streams in Node.js are a type of stream that combines the features of both readable and writable streams, allowing for two-way communication. With duplex streams, you can both read data from a source and write data to a destination concurrently, making them bidirectional. Common use cases for duplex streams include implementing network protocols like WebSockets, where you need to both receive and send data over a single connection, or interactive communication channels like chat applications, where messages are sent and received in real-time.
const fs = require('fs')
const { PassThrough } = require('stream')
const readable = fs.createReadStream('./data.txt', {highWaterMark: 1024 * 1024 * 5})
const writable = fs.createWriteStream('./data_new.txt')
const tunnel = new PassThrough()
tunnel.on('data', data => console.log(`Byte length: ${data.length}`)) // data event is readable stream property
readable.pipe(tunnel).pipe(writable) // readable can pass data to writable stream through pipe
Transform
A transform stream, in essence, is a specialized type of duplex stream designed for altering or transforming data as it's both written to and read from the stream. A practical example of this is the use of zlib.createGzip stream, which compresses data using the gzip format. You can visualize a transform stream as a function that takes data on one end, the writable stream part processes it, and then provides the transformed data on the other end, the readable stream part. In some discussions, you might come across the term through streams as another way to refer to transform streams.
const fs = require('fs')
const { Transform } = require('stream')
const readable = fs.createReadStream('./data.txt', {highWaterMark: 1024 * 1024 * 5})
const writable = fs.createWriteStream('./data_new.txt')
Transform.prototype._transform = function (chunk, encoding, callback) {
this.push(`${chunk.toString('base64')}\n`)
console.log(chunk.length)
callback()
}
const tunnel = new Transform()
readable.pipe(tunnel).pipe(writable)
Streams Practical Examples
Initially, we'll set up a readable stream. This stream is responsible for storing strings in memory as buffers. To start, we'll add a new string to the buffer.
const Stream = require('stream')
const readable = new Stream.Readable()
readable.push('Hello\t')
readable.push('Developers')
readable.push(null)
readable.pipe(process.stdout)
// Hello Developers
process.stdout is a writeable stream. A readable stream acts like a helper that reads data from a source and writes it into memory. Think of it as a student reading a book page by page and jotting down the information. As the stream reads, it keeps storing the data in memory. When it reaches the end of the source data, it adds a special note, called "stream null," which signals that it has finished writing into memory. This is a way of saying, "I've read everything, and I'm done!"
Another way to write data into memory is by using something called an "async iterator." This is a helpful tool when you have a lot of information, and you want to put it into a stream. It's similar to having a special hand that can pick specific pieces of data and place them into the stream. Just like when you have a collection of toys, and you want to choose the ones you'd like to play with – the async iterator acts like your selecting hand, putting the chosen data into the stream. It's a convenient method when you only need certain parts of the data in your stream.
const Stream = require('stream')
async function* generate() {
for (let i =0; i < 10; i++) {
yield Buffer.from(`${i}\t`)
}
}
const readable = Stream.Readable.from(generate())
readable.pipe(process.stdout)
// 0 1 2 3 4 5 6 7 8 9
The readable.pipe() method connects a writable stream to a readable stream, and it allows data to flow from the readable stream into the writable stream. Pipe method does not return anything. When you're dealing with large files, performing tasks like creating zip archives, saving data to disk, or sending it over a network, your application might run into a problem where it tries to store more data in memory than it can handle. This situation is known as Backpressuring. To address this challenge, Node.js provides a built-in solution through the stream pipe method, which helps manage this substantial memory usage efficiently.
How is Backpressuring prevented?
When you hear about 'backpressure,' it's all about knowing when a system needs to slow down or pause to handle data. In the world of streams, this moment happens when the 'write()' function in a writable stream returns 'false.' It returns 'false' when a few things occur. First, if the data being sent gets too big or if the system is busy and can't handle more data, 'write()' says, 'I can't take more right now.' When it says 'false,' the system pauses the readable stream from sending any more data. It waits until things calm down. Once there's room for more data, it sends a signal ('drain' event) saying, 'Okay, we're ready again,' and the data flow continues." This process is how streams manage and control data flow when things get busy, ensuring they don't overwhelm the system.
// Max memory usage 42 MB
const fs = require('fs')
const readable = fs.createReadStream('./high.mp4') // 6.6gb
const writable = fs.createWriteStream('./new.mp4')
readable.pipe(writable)
Why use Pipeline instead of pipe?
You should opt for the pipeline() method over the use of .pipe() in production applications. There are several compelling reasons for this recommendation. Notably, when one of the piped streams is closed or encounters an error, pipe() lacks the automatic mechanism to handle the destruction of connected streams, potentially resulting in memory leaks within your applications. Additionally, pipe() does not offer the convenience of automatically forwarding errors across streams to a central location for efficient error handling.
In response to these issues, the pipeline() method was introduced to cater to these specific problems. Hence, to ensure smoother and more reliable stream connections in your production applications, it is strongly advised that college students make use of the pipeline() method. pipeline method passes buffer/string in sequential order.
const { pipeline } = require("stream");
const fs = require('fs')
const readable = fs.createReadStream('./hello.txt') // 6.6gb
const writable = fs.createWriteStream('./new.txt')
pipeline(readable, writable, (err) => {
err && console.error(err);
});
